
什么是散列表
散列表来源于数组,它借助散列函数对数组这种数据结构进行扩充,利用的是支持按照下标随机访问元素的特性,它最大的特点就是查找、插入、删除的平均时间复杂度接近 O(1)
散列表两个核心问题是 散列函数设计和散列冲突解决。散列冲突有两种常用的解决方式,开放寻址法和链表法,散列函数设计的好坏决定了散列冲突的概率,也就决定了散列表的性能。
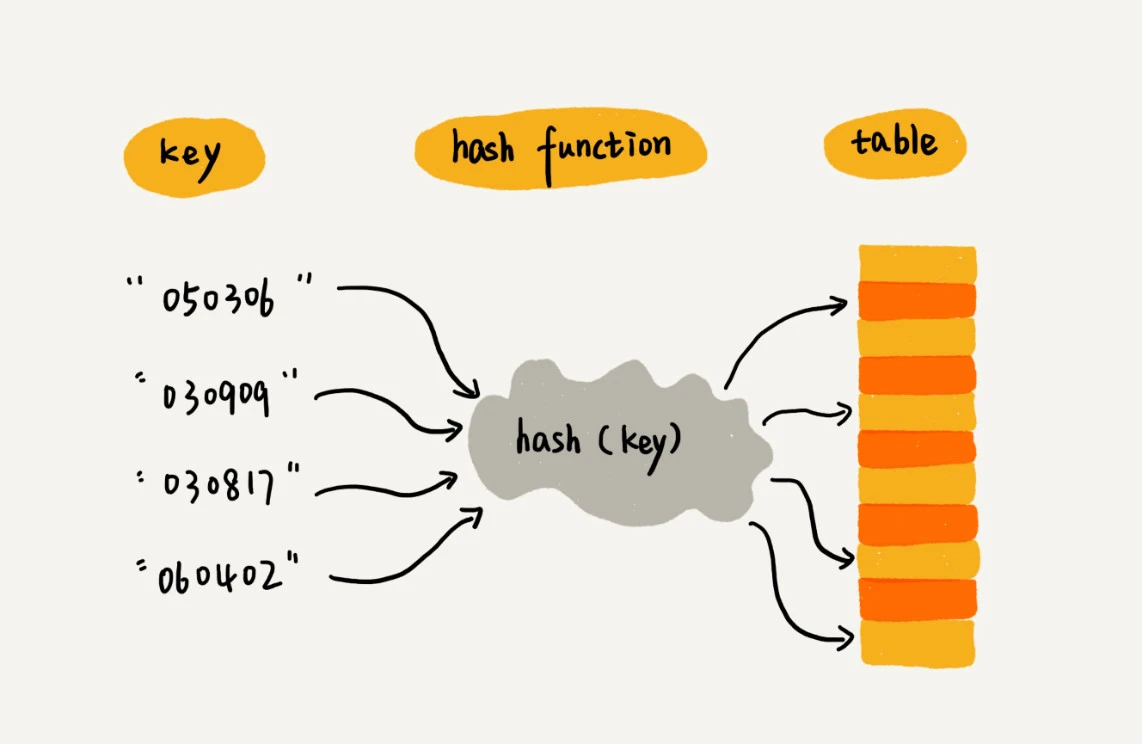
散列表的构成
(1)哈希函数(Hash Function)
作用:把任意类型的键映射到数组的索引。
好的哈希函数应该:
分布均匀(减少碰撞)
计算高效(不能太慢)
确定性(相同输入一定得到相同输出)
例子:
int Hash(string key, int capacity)
{
int hash = 0;
foreach (char c in key)
{
hash = (hash * 31 + c) % capacity;
}
return hash;
}
(2)碰撞处理(Collision Resolution)
因为哈希值的范围有限,不同的键可能映射到相同位置,这就叫碰撞。
常见解决方法:
链地址法(Separate Chaining)
每个数组位置存一个链表(或动态数组),发生碰撞就把元素插到链表里。
优点:实现简单
缺点:链表过长会影响性能
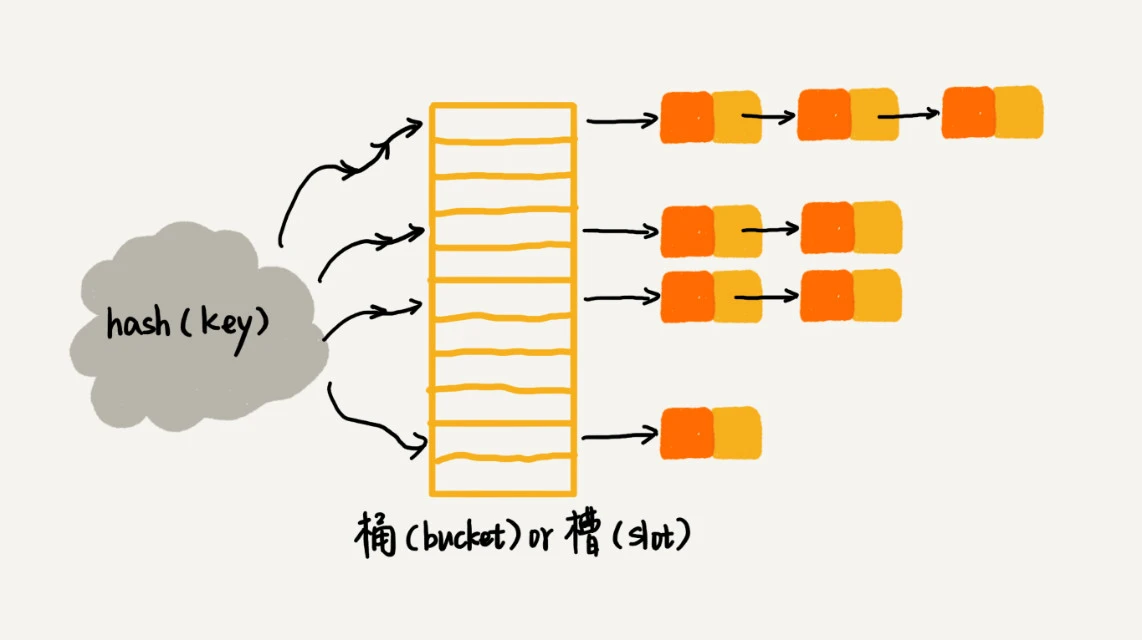
开放寻址法(Open Addressing)
如果位置被占了,就找下一个空位(线性探测、二次探测、双重哈希等)。
优点:节省指针开销
缺点:装填因子高时性能下降
制作一个工业级散列表需要注意的事项
具有的特性
支持快速的查询,插入,删除操作
内存占用合理,不能浪费过多的内存空间
性能稳定,极端情况下,散列表的性能不会退化到无法接受的情况
设计散列表的思路
设计一个合适的散列函数
定义装载因子阈值,并且设计动态扩容策略
设计合适的散列冲突解决方法
其他
关于散列函数的设计,我们要尽可能让散列后的值随机且均匀分布,这样会尽可能地减少散列冲突,即便冲突之后,分配到每个槽内的数据也比较均匀。除此之外,散列函数的设计也不能太复杂,太复杂就会太耗时间,也会影响散列表的性能。
关于散列冲突解决方法的选择,我对比了开放寻址法和链表法两种方法的优劣和适应的场景。大部分情况下,链表法更加普适。而且,我们还可以通过将链表法中的链表改造成其他动态查找数据结构,比如红黑树,来避免散列表时间复杂度退化成 O(n),抵御散列碰撞攻击。但是,对于小规模数据、装载因子不高的散列表,比较适合用开放寻址法。
对于动态散列表来说,不管我们如何设计散列函数,选择什么样的散列冲突解决方法。随着数据的不断增加,散列表总会出现装载因子过高的情况。这个时候,我们就需要启动动态扩容。